Webscraping ALLSTAT
Life on the edge of easy responsible webscraping
As underlined in The Ethical Scraper’s principles by James Densmore (that I found in the slides of Hanjo Odendaal’s useR! 2018 webscraping tutorial), a first step is to research whether you can get the data without webscraping (I found no API). Note that an ideal case would be to have received emails since the list’s creation in 1998, and having stored them, so that one could use this local copy. Or one could email the list maintainers of course!
Then, there is some good practice to keep in mind whilst webscraping, also underlined in the principles list, and most importantly all encompassed in the awesome new package polite by Dmytro Perepolkin! I knew the packages wrapped by Dmytro, but tended to only use robotstxt e.g. here when webscraping, (but using others in API packages). Now with very little effort, with polite you will
Seek permissions via
robotstxt,Introduce yourself with an user agent, by default the package’s name and URL,
Take it slowly thanks to
ratelimitr,Never ask twice thanks to
memoise.
The polite package is brand-new, still in development, which in general means you might want to stay away from it for a while, but I was eager to try it and pleased by its working very well! Being an early adopter also means I saw my issues promptly closed with some solution/new code by Dmytro!
I started work by bowing which in polite’s workflow means both creating a session (with user-agent, delay between calls) and checking that the path is allowed.
home_url <- "https://www.jiscmail.ac.uk/cgi-bin/webadmin"
session <- polite::bow(home_url,
user_agent = "Maëlle Salmon https://masalmon.eu/")And then it was time to scrape and parse…
Actual webscraping a.k.a solving XPath puzzles
When confronted with a page I’d like to extract info from, I try to identify how I can write XPath to get the elements I want, which means looking at the page source. I used to transform whole pages to text before using regexp on them, which was clearly suboptimal, thanks to Eric Persson for making me switch to XPath.
My strategy here was to get the subject, date, sender and size of each email from archive pages. Here is such an archive page. Nowadays there is one archive page by month, but there used to be one by year, so I got the list of archive pages from this general page.
library("magrittr")
polite::scrape(session, params = "?A0=ALLSTAT") %>%
rvest::xml_nodes("li") %>%
rvest::xml_nodes("a") %>%
rvest::html_attr("href") %>%
purrr::keep(function(x) stringr::str_detect(x, "\\/cgi-bin\\/webadmin\\?A1\\=")) %>%
stringr::str_remove("\\/cgi\\-bin\\/webadmin\\?A1\\=ind") %>%
stringr::str_remove("\\&L\\=ALLSTAT") -> date_stringsThis is not very elegant but this got me only the “1807” and such I needed for the rest of the scraping. polite::scrape is a wrapper to both httr::GET and httr::content and does the rate limiting (by default 1 call every 5 seconds, delay parameter of polite::bow) and memoising. I actually ended up only scraping emails metadata from 2007 because it took ages to parse the 2006 page. It made me, according to a search via the website, miss these data scientists job openings: one in 2000 and one in 2004.
date_strings <- date_strings[stringr::str_length(date_strings) != 2]
# or
date_strings <- purrr::discard(date_strings, function(x) stringr::str_length(x) == 2)I created a function getting the metadata out of each archive page. The trickiest points here were:
That the rows of the archive table could have two classes, which is the way alternate coloring was obtained. I therefore used
|in XPath'//tr[@class="normalgroup"]|//tr[@class="emphasizedgroup"]'.That there was no different class/formatting for subject, date, sender, so I got all of them at once, and then used the modulo operator,
%%, to assign them to the right vector.
get_emails_meta_by_date <- function(date_string, session){
message(date_string)
params <- glue::glue("?A1=ind{date_string}&L=ALLSTAT&F=&S=&O=T&H=0&D=0&T=0")
everything <- try(polite::scrape(session, params = params),
silent = TRUE)
# at the time of writing one couldn't pass encoding to scrape
# but now one can https://github.com/dmi3kno/polite/issues/6#issuecomment-409268730
if(is(everything, "try-error")){
everything <- httr::GET(paste0(home_url,
params)) %>%
httr::content(encoding = "latin1")
}
everything <- everything %>%
# there are two classes that correspond
# to the table having two colours of rows!
rvest::xml_nodes(XPath = '//tr[@class="normalgroup"]|//tr[@class="emphasizedgroup"]') %>%
rvest::xml_nodes("span")
everything %>%
rvest::xml_nodes(XPath = "//td") %>%
rvest::xml_nodes("span") %>%
rvest::xml_nodes("a") %>%
rvest::html_text() -> subjects
everything %>%
rvest::xml_nodes(XPath = "//td[@nowrap]") %>%
rvest::xml_nodes(XPath = "p[@class='archive']") %>%
rvest::html_text() -> big_mess
senders <- big_mess[seq_along(big_mess) %% 3 == 1]
senders <- stringr::str_remove(senders, " \\<\\[log in to unmask\\]\\>")
dates <- big_mess[seq_along(big_mess) %% 3 == 2]
dates <- lubridate::dmy_hms(dates, tz = "UTC")
sizes <- big_mess[seq_along(big_mess) %% 3 == 0]
sizes <- stringr::str_remove(sizes, " lines")
sizes <- as.numeric(sizes)
tibble::tibble(subject = subjects,
sender = senders,
date = dates,
size = sizes) %>%
readr::write_csv(glue::glue("data/emails_meta{date_string}.csv"))
}I chose to save the metadata of each archive page in its own csv in order to make my workflow less breakable. I could have used purrr::map_df but then it’d be harder to re-start, and it was hard on memory apparently.
fs::dir_create("data")
purrr::walk(date_strings,
get_emails_meta_by_date,
session = session)Analyzing ALLSTAT jobs
Filtering jobs
ALLSTAT encourages you to use keywords in emails’ subjects, so many job openings contain some variant of “job”, and that’s the sample on which I shall work.
library("magrittr")
library("magrittr")
fs::dir_ls("../../static/data/allstat") %>%
purrr::map_df(readr::read_csv) -> emails
jobs <- dplyr::filter(emails,
stringr::str_detect(subject,
"[Jj][Oo][Bb]"))Out of 32761 emails I got 9245 job openings.
I created two dummy variables to indicate the presence of data scientist or statistician in the description. With the definition below, the “statistician” category might contain “biostatitisticians” which is fine by me.
jobs <- dplyr::mutate(jobs,
data_scientist = stringr::str_detect(subject,
"[Dd]ata [Ss]cientist"),
statistician = stringr::str_detect(subject,
"[Ss]tatistician"))176 subjects contain the word “data scientist”, 2546 the word “statistician.”, 20 both.
dplyr::filter(jobs, data_scientist, statistician) %>%
dplyr::select(subject, sender, date) %>%
knitr::kable()| subject | sender | date |
|---|---|---|
| JOB: Statisticians/Data Scientists with Unilever | Murray, Peter | 2008-02-12 08:47:56 |
| Jobs: Senior Data Scientists/Statisticians | Cox, Trevor | 2008-03-12 16:24:48 |
| 20 new job ads for data scientists, statisticians | Vincent Granville | 2013-06-16 00:18:27 |
| 23 new jobs for statisticians, data scientists | Vincent Granville | 2013-07-27 20:05:48 |
| 19 new job ads for statisticians and data scientists | Vincent Granville | 2013-10-12 23:21:23 |
| Job Data scientist / Statistician | Andrea Schirru | 2014-07-22 16:38:59 |
| JOB: Computational Statistician / Data Scientist | David Hastie | 2014-07-16 11:36:34 |
| Job Openings: Statisticians and Data Scientists at Open Analytics (Belgium) | Tobias Verbeke | 2015-06-30 09:53:21 |
| JOBS x 2: Data Scientist/Medical Statistician at University of Manchester | Matthew Sperrin | 2016-07-28 10:42:52 |
| JOB: Data scientist - Statistician (KTP associate) @ University of Essex | Aris Perperoglou | 2016-09-12 10:33:32 |
| JOB: Principal Statistician/ Data Scientist- Pharma - Perm - Centralised Monitoring- Data Safety - Global Search-UK | Sabrina Andresen | 2016-10-17 16:05:12 |
| JOB: Research Associate - Statistician / Data Scientist, University of Manchester (Centre for Musculoskeletal Research) | Jamie Sergeant | 2016-11-01 10:21:07 |
| JOB - Statistician / Data Scientist at Cefas, UK | David Maxwell | 2017-08-04 16:15:25 |
| Job: Data Scientist/Statistician at Essex University | Aris Perperoglou | 2017-08-21 13:43:43 |
| Job: Statistician/Data Scientist | Roisin McCarthy | 2017-11-06 16:49:18 |
| Job Openings: Statisticians and Data Scientists at Open Analytics (Belgium) | Tobias Verbeke | 2017-12-05 20:48:39 |
| JOB | StatsJobs - Data Scientist/Statistician, Zurich Insurance | James Phillips | 2018-01-30 08:59:49 |
| JOB | Junior Medical statistician / Real-world data scientist - Centre of Excellence for Retrospective Studies, IQVIA (London) | Venerus, Alessandra | 2018-03-05 10:33:09 |
| JOB | Senior Medical statistician / Real-world data scientist - Centre of Excellence for Retrospective Studies, IQVIA (London) | Venerus, Alessandra | 2018-03-05 10:32:51 |
| Job: Catalyst Project Research Data Scientist / Statistician | Aris Perperoglou | 2018-06-25 14:17:18 |
Are the job titles synonymous for the organizations using slashes? I am especially puzzled by “Senior Medical statistician / Real-world data scientist”! I filtered them out and created a category variable.
jobs <- dplyr::filter(jobs,
!(data_scientist&statistician))
jobs <- dplyr::mutate(jobs,
category = dplyr::case_when(data_scientist ~ "data scientist",
statistician ~ "statistician",
TRUE ~ "other"),
category = factor(category,
levels = c("statistician",
"data scientist",
"other"),
ordered = TRUE))
jobs <- dplyr::mutate(jobs,
year = lubridate::year(date),
year = as.factor(year))Here are some examples of positions for each:
head(jobs$subject[jobs$category=="statistician"])## [1] "FW: JOB: Senior/Lead Statistician - GlaxoSmithKline"
## [2] "JOB - Clinical Trial Statisticians and SAS Programmers"
## [3] "JOB - Medical statistician in Salvador, Brazil (2-3 years)"
## [4] "JOB - Medical Statistician, Oxford"
## [5] "JOB OPPORTUNITY - 39408 - Entry-Level Statisticians - GSK"
## [6] "JOB: Biostatistician - Contract/Consultancy Opportunity - Switzer land"head(jobs$subject[jobs$category=="data scientist"])## [1] "JOB: Data Scientist, Unilever"
## [2] "JOB: Data Scientist, Unilever"
## [3] "JOB: Data Scientist / Machine Learning (BELFAST)"
## [4] "JOB: Data Scientists in Belfast"
## [5] "JOBS: Data Scientists"
## [6] "[Job] Hacker or Botnet Developer, Data Scientist (Telecommute)"head(jobs$subject[jobs$category=="other"])## [1] "Job - Data manager Dept of Haematology, Imperial College, London"
## [2] "Re: JOB - Health Economic Modelling and Value Demonstrations"
## [3] "JOB - Lectureship / readership"
## [4] "JOB - Mathematical Modeller at the Health Protection Agency, Centre for Infections"
## [5] "JOB - PhD position"
## [6] "JOB - SAS Senior Statistical Programmer, Oxford"Are data scientists on the rise?
library("ggplot2")
ggplot(jobs) +
geom_bar(aes(year, fill = category)) +
viridis::scale_fill_viridis(discrete = TRUE) +
theme(legend.position = "bottom") +
hrbrthemes::theme_ipsum(base_size = 14) +
xlab("Year (2018 not complete yet)") +
ylab("Number of job openings") +
theme(axis.text.x = element_text(angle = 90, hjust = 1)) +
ggtitle("ALLSTAT mailing list 2007-2018")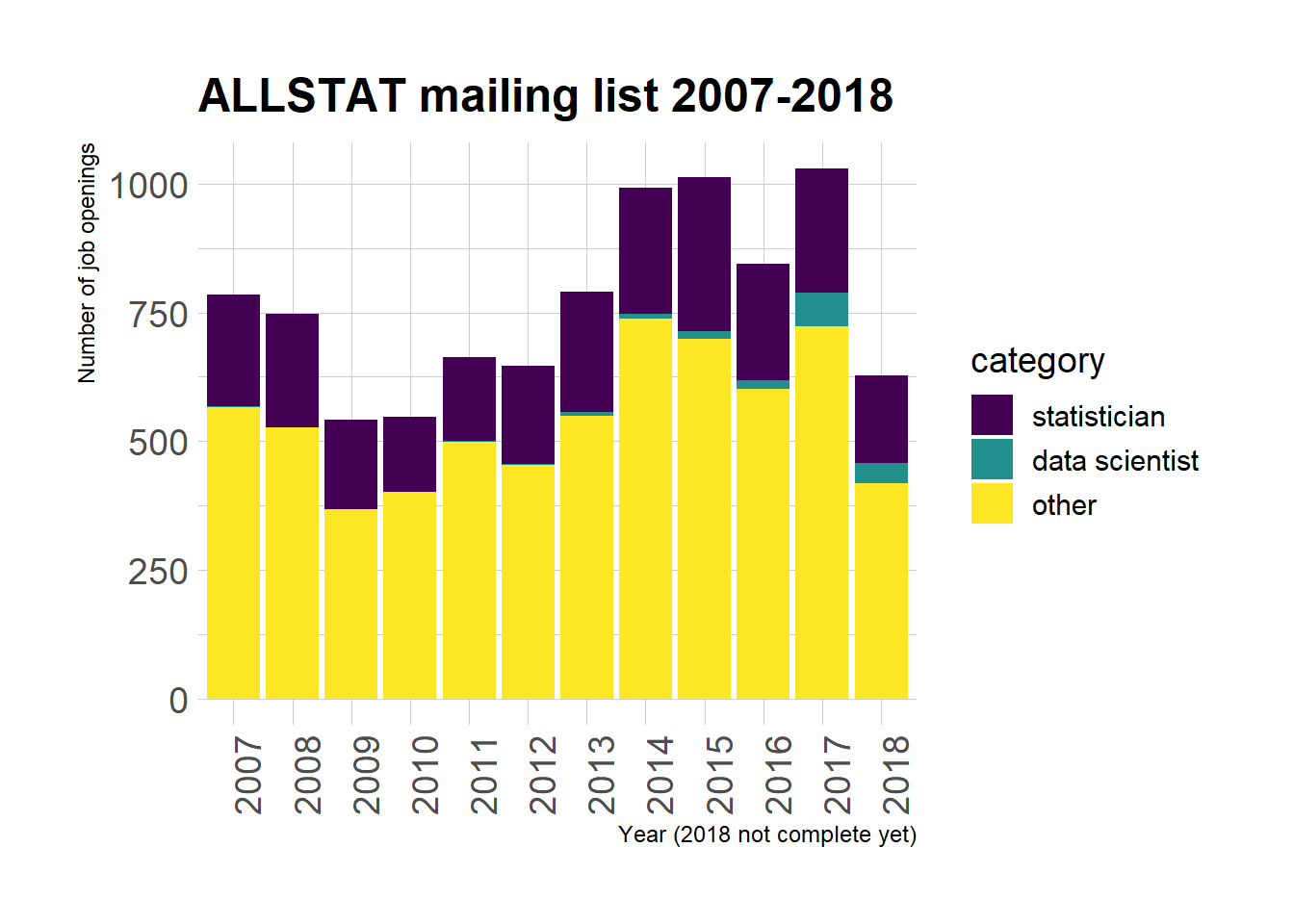
I like this bar plot that shows how the total number of job openings fluctuates, but it’s hard to see differences in proportions.
ggplot(jobs) +
geom_bar(aes(year, fill = category),
position = "fill") +
viridis::scale_fill_viridis(discrete = TRUE) +
theme(legend.position = "bottom") +
hrbrthemes::theme_ipsum(base_size = 14) +
xlab("Year (2018 not complete yet)") +
ylab("Number of job openings") +
theme(axis.text.x = element_text(angle = 90, hjust = 1))+
ggtitle("ALLSTAT mailing list 2007-2018")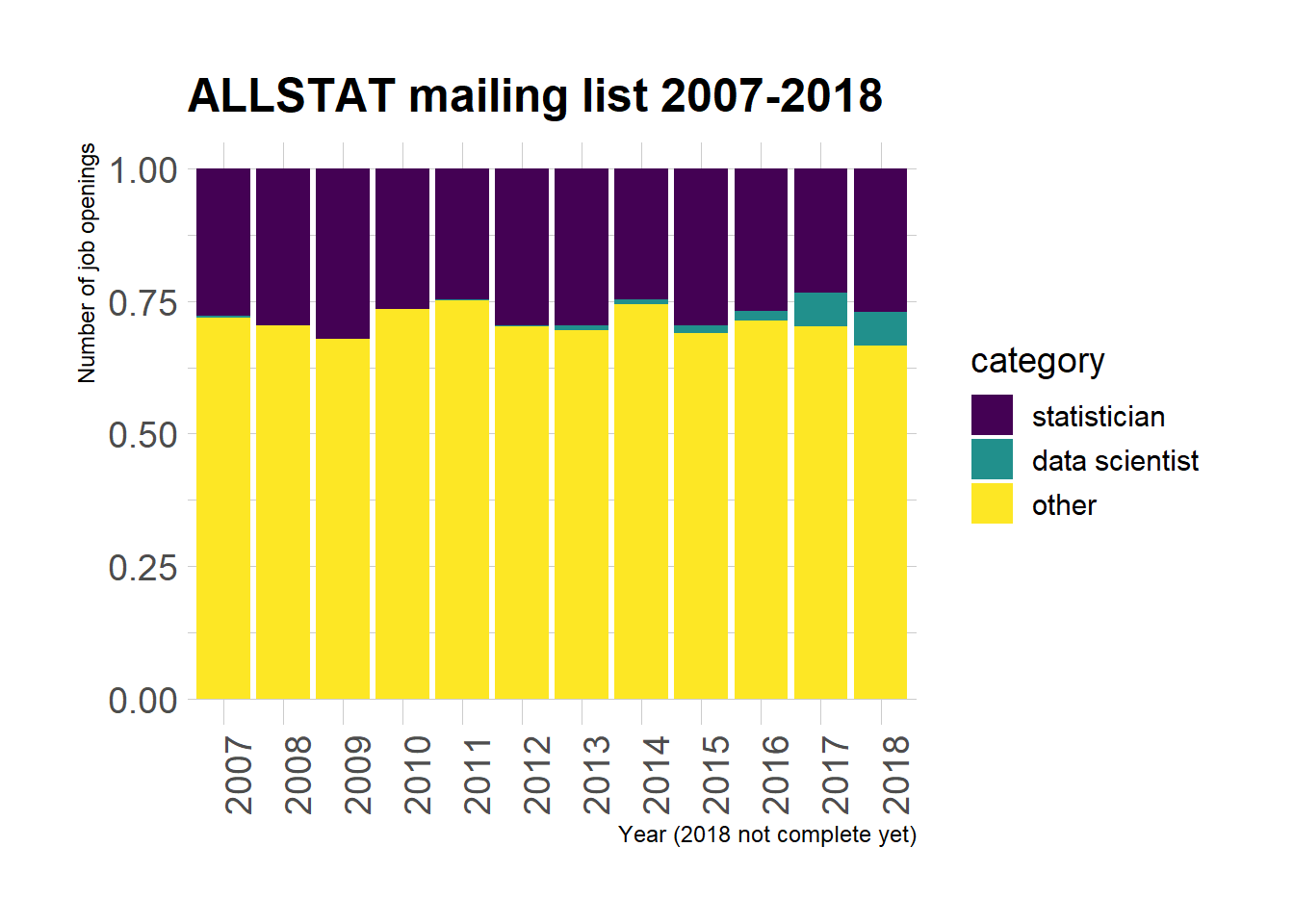
According to this plot, although there seems to be more and more data scientists’ jobs advertised on ALLSTAT… Statisticians don’t need to get worried just yet.
Who offers data scientists’ jobs?
dplyr::count(jobs, category,
sender) %>%
dplyr::group_by(category) %>%
dplyr::arrange(category, - n) %>%
dplyr::filter(sender %in% sender[1:5])## # A tibble: 15 x 3
## # Groups: category [3]
## category sender n
## <ord> <chr> <int>
## 1 statistician James Phillips 106
## 2 statistician Sabrina Andresen 82
## 3 statistician James Miller 45
## 4 statistician Angela Smythe 40
## 5 statistician Helena Newman-Mitchell 37
## 6 data scientist James Phillips 86
## 7 data scientist Sportradar HR 5
## 8 data scientist Jason Howlin 4
## 9 data scientist Deborah Gee 3
## 10 data scientist Christos Mitas 2
## 11 other James Phillips 671
## 12 other Angela Smythe 223
## 13 other Helena Newman-Mitchell 103
## 14 other Jason Howlin 91
## 15 other James Miller 85Seeing James Phillips’ name so often made me have a look at their emails: this person sends emails on the behalf of a website called StatsJobs.com! We can also assume that other super-senders actually work for job aggregators of some sort.
What are the openings about?
To make a more thorough description of the different categories, one would need to get the email bodies, which I decided against for this post. I simply used the subjects, and compared word usage between the “data scientist” and “statistician” categories as in this chapter of the Tidy text mining book by Julia Silge and David Robinson.
library("tidytext")
data("stop_words")
words <- dplyr::filter(jobs, category != "other") %>%
unnest_tokens(word, subject, token = "words") %>%
dplyr::filter(!word %in% stop_words$word,
!word %in% c("job", "statistician",
"jobs", "statisticians",
"data", "scientist",
"scientists",
"datascientistjobs"))
word_ratios <- words %>%
dplyr::count(word, category) %>%
dplyr::group_by(word) %>%
dplyr::filter(sum(n) >= 10) %>%
dplyr::ungroup() %>%
tidyr::spread(category, n, fill = 0) %>%
dplyr::mutate_if(is.numeric, dplyr::funs((. + 1) / sum(. + 1))) %>%
dplyr::mutate(logratio = log(`data scientist` / statistician)) %>%
dplyr::arrange(desc(logratio))
word_ratios %>%
dplyr::group_by(logratio < 0) %>%
dplyr::top_n(15, abs(logratio)) %>%
dplyr::ungroup() %>%
dplyr::mutate(word = reorder(word, logratio)) %>%
ggplot(aes(word, logratio, fill = logratio < 0)) +
geom_col(show.legend = FALSE) +
coord_flip() +
ylab("log odds ratio (data scientist / statistician)") +
scale_fill_manual(name = "",
values = c("#21908CFF", "#440154FF"),
labels = c("data scientist", "statistician")) +
hrbrthemes::theme_ipsum(base_size = 11)+
ggtitle("ALLSTAT mailing list 2007-2018")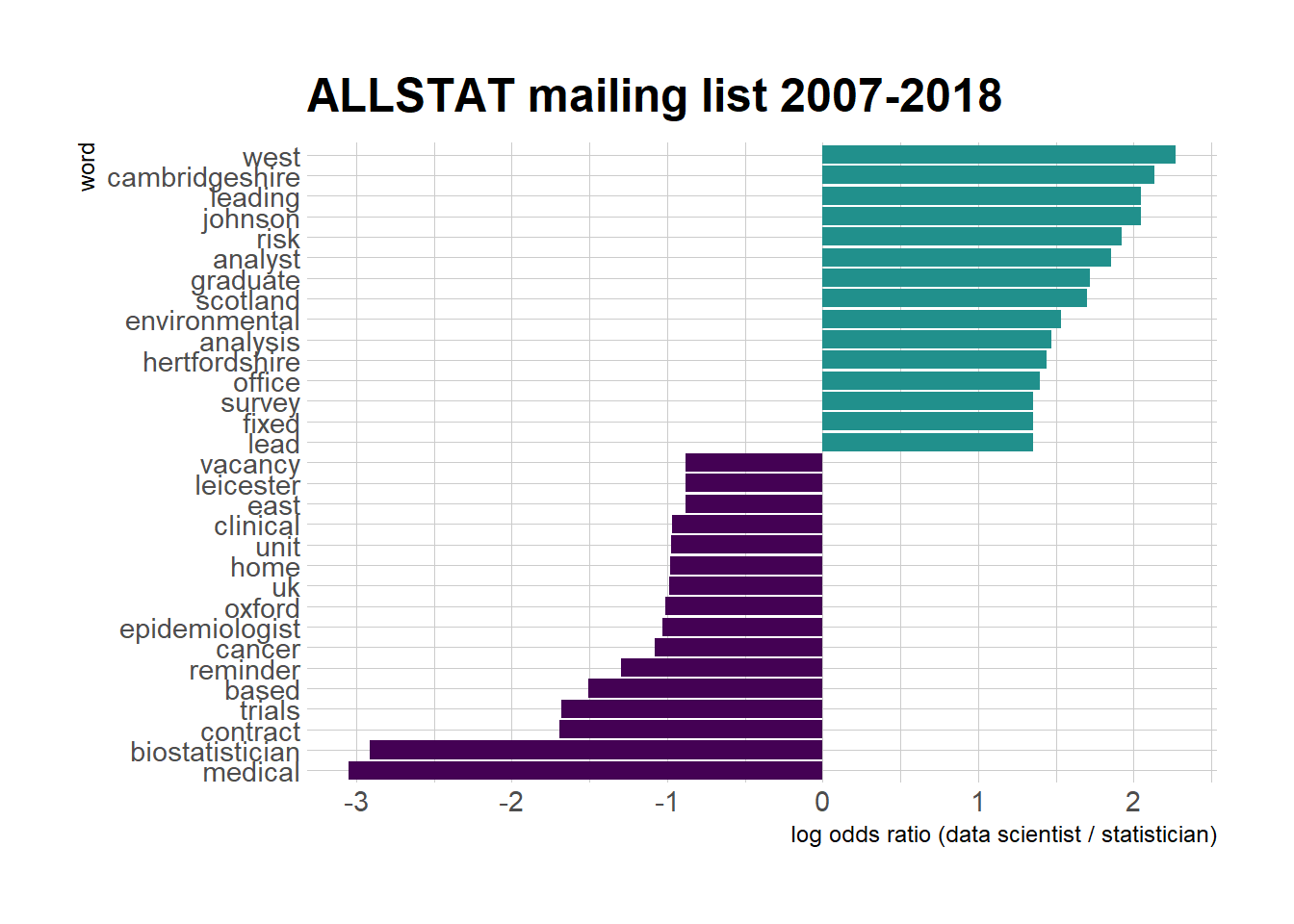
What does this figure show? On the left are words more frequent in statistician job openings, on the right words more frequent in data scientist job openings. Well, there might be geographical clusters for each of the category, which I don’t believe though: is the data scientist vs. statistician debate a Cambridgeshire vs. Oxford battle? I was surprised that no word related to academia made an appearance because I thought “university” or an equivalent word would be more representative of statisticians. I am less surprised, though, by words such as “trials”, “medical”, “clinical” being more prevalent in the “statistician” category. The word “fixed” as in “fixed-term” contract is more prevalent for data scientist job openings, which doesn’t sound too cool?
Conclusion
In this post, I had the pleasure to use the brand-new polite package that made responsible webscraping very smooth! Armed with that tool, I extracted metadata of job openings posted on the ALLSTAT mailing lists. I made no statistical analyses, but the main take-away is that statisticians aren’t in danger of extinction just yet.