My husband and I recently started watching the wonderful series “Parks and recreation” which was recommended to me by my fellow R-Lady Jennifer Thompson in this very convincing thread. The serie was even endorsed by other R-Ladies. Jennifer told me the first two seasons are not as good as the following ones, but that it was worth it to make it through them. We actually started enjoying the humor and characters right away!
Then, this week while watching the show, one of the characters did a very basic text analysis that made me feel like imitating him for a blog post – my husband told me it was very Leslie of me to plan something while doing something else which made me very proud. I tested my idea on other Leslie fans, and they seemed to think it was a great idea… and that this post should be the beginning of a series of R-Ladies blog posts about Parks and recreation!
In this two-short-part blog post, I’ll therefore inaugurate this series, what an honor!
Less than stellar first seasons?
Jennifer told me the first two seasons were not the best ones. My brother who is a cruel man (just kidding) told me this was a very good joke idea: you tell someone a very bad TV series starts getting awesome after a few seasons that you need to watch in order to know the characters… therefore forcing them to loose their time and sanity in front of the screen, ah! Luckily Jennifer wasn’t doing that.
I said my husband and I were hooked on the series right from the first episode… what about other people? To answer this question, I downloaded IMDB ratings for the show! I first tried using R packages accessing the OMDB API, but this one was outdated and this up-to-date one was not but taught me the API no longer returns ratings by season… So I scraped the IMDB website using the rvest package, after checking I was allowed to do so thanks to the robotstxt package.
robotstxt::paths_allowed("http://www.imdb.com/title/tt1266020/eprate")
## [1] TRUE
library("rvest")
imdb_page <- html("http://www.imdb.com/title/tt1266020/eprate")
ratings <- imdb_page %>%
html_nodes("table") %>%
.[[1]] %>%
html_table() %>%
.[,1:4]
knitr::kable(ratings[1:5,])
| # | Episode | UserRating | UserVotes |
|---|---|---|---|
| 7.13 | One Last Ride: Part 2 | 9.7 | 2,407 |
| 7.12 | One Last Ride: Part 1 | 9.6 | 1,934 |
| 7.40 | Leslie and Ron | 9.6 | 1,842 |
| 6.22 | Moving Up: Part 2 | 9.4 | 1,273 |
| 5.14 | Leslie and Ben | 9.3 | 1,205 |
I just had to wrangle this table a little bit.
names(ratings)[1] <- "number"
ratings <- tidyr::separate(ratings, col = number,
into = c("season", "episode"),
sep = "\\.")
ratings <- dplyr::mutate(ratings, UserVotes = stringr::str_replace(UserVotes, ",", ""))
ratings <- dplyr::mutate(ratings, UserVotes = as.numeric(UserVotes))
ratings <- dplyr::mutate(ratings, episode = as.numeric(episode))
And then I could at last plot the ratings and see whether the two first seasons were not that loved! Before that I quickly assessed whether there was an ok number of votes for all episodes, and that this did not vary widely over seasons, which was the case.
library("ggplot2")
library("hrbrthemes")
ggplot(ratings, aes(episode, UserRating,
color = season)) +
geom_smooth()+
geom_point() +
ylab("IMDB rating") +
viridis::scale_color_viridis(discrete = TRUE) +
theme_ipsum(base_size = 20,
axis_title_size = 20)
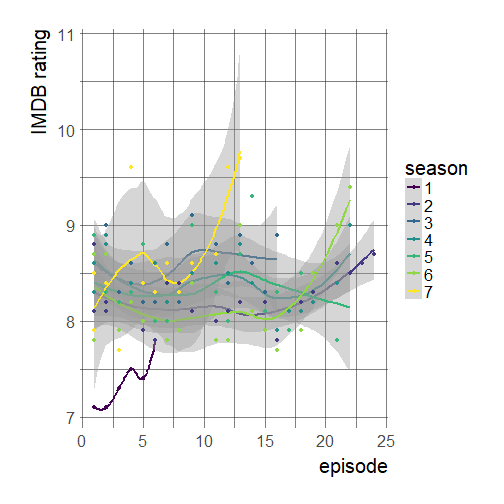
Note that for the first season, there are too few points for actually doing a smoothing. Looking at the plot I guess we can say the first season with its only 6 episodes was slightly less enjoyed! I am very thankful that the first season was deemed good enough to continue the series though! Besides I am thankful that it was so simple to answer this crucial question.
Leslie’s wordcloud
Warning: the wordcloud produced here might be a spoiler if you have not watched the 4 first seasons!
In the 10th episode of season 4, Tom produces a wordcloud of Leslie’s emails and memos. I cannot really do the same, but was inspired to make a worldcloud of things said in the episodes by downloading all subtitles from the 4 first seasons and using the fantastic subtools package. Note that a worldcloud is probably not the coolest thing one can do with all these text data… but it is a start and I truly hope it inspires more people to use François Keck’s package which is really user-friendly since it can read all the subtitles of a serie at once from a folder where each sub-folder is a season. It also supports conversion to formats suitable for text analysis!
The single problem I experienced when doing this work was that I had to download subtitles from the internet and the websites where you find those are not cute places, they’re full of “women to date”…
To make the wordcloud I very simply followed this blog post of François Keck’s. It doesn’t get easier than that… which is great given I have very little time at the moment.
library("subtools")
library("tm")
library("SnowballC")
library("wordcloud")
parks_and_rec <- read.subtitles.serie(dir = paste0(getwd(), "/data/pr/"))
## Read: 4 seasons, 68 episodes
corpus <- tmCorpus(parks_and_rec)
corpus <- tm_map(corpus, content_transformer(tolower))
corpus <- tm_map(corpus, removePunctuation)
corpus <- tm_map(corpus, removeNumbers)
corpus <- tm_map(corpus, removeWords, stopwords("english"))
corpus <- tm_map(corpus, stripWhitespace)
TDM <- TermDocumentMatrix(corpus)
TDM <- as.matrix(TDM)
vec.season <- c(rep(1, 6), rep(2, 24), rep(3, 16), rep(4, 22))
TDM.season <- t(apply(TDM, 1, function(x) tapply(x, vec.season, sum)))
colnames(TDM.season) <- paste("S", 1:4)
set.seed(1)
comparison.cloud(TDM.season, title.size = 1, max.words = 100, random.order = T)
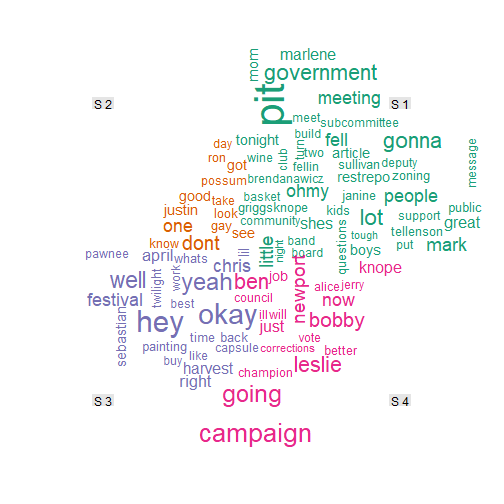
It doesn’t look anything like Leslie’s wordcloud but it made me happy because I had already forgotten about some words or names from the previous seasons!
Another thing I did with the subtitles was filtering those starting with “Oh Ann” in order to have a look at some of the terrific compliments Leslie made to Ann… And one of them inspired the title of this post, replacing “baby” by “series”!
The end of this post, the beginning a series!
Now that I’ve done my homework I’m truly looking forward to reading the other posts. I can’t wait! Stay tuned by following my fellow bloggers/Leslie fans who came out in this Twitter thread.