I am a runner but also a Body Pump enthusiast. Body Pump is a group fitness class of the Les Mills company, in which you train different muscle groups using a weighted bar – whose total weight you modulate with plates in order to adapt it to your fitness level and to the muscle group. Like R, Body Pump was created in New Zealand, what a wonderful country! Every three months, a new class is released, with new songs and choreographies. What doesn’t change is the muscle group trained in each of the 10 songs of each class.
I’ve thought of analysing Body Pump data for a long time now but could never find what I was looking for, which was a dataset of number of “reps” by song, e.g. how many squats do you do in each squats song. Then I realized I could also play with other data, like a quite comprehensive list of songs used in releases. I decided to cross this information with information about style of the corresponding artist in Spotify. Here is what I came up with!
Track 1: Track list cleaning
This I did listening to pop music, actually using my husband’s Deezer account. I downloaded data from this page which is quite exhaustive for many releases but well not formatted in a consistent way over releases, so I needed to be patient. A bit like when in the triceps track one does many half repetitions and feels one’s arms are going to fall off.
library("rvest")
pg <- "http://www.blogforumsupport.com/2008/bodypump2008.html"
pg_content <- read_html(pg, encoding = "latin1")
save(pg_content, file = "data/pg_content.RData")
Then I extracted the track lists, in a non very elegant way. Sometimes one just wants the job done…
library("magrittr")
xtract_nodes <- function(node, css) {
html_nodes(node, css) %>% html_text(trim = TRUE)
}
tracks <- xtract_nodes(pg_content, 'p')
tracks <- tracks[grepl("1", tracks) & grepl("2", tracks) & grepl("9", tracks) & grepl("10", tracks)]
tracks <- unlist(tracks)
What follows is scripted manual correction of some mistakes in the data, or things that makes later extraction of title vs. artist a bit complicated.
tracks <- stringr::str_replace(tracks,
"04. Campione 2012 - DJ Flow05. 50 Ways to Say Goodbye - Train",
"04. Campione 2012 - DJ Flow \n 05. 50 Ways to Say Goodbye - Train")
tracks <- stringr::str_replace(tracks,
"Upion Havoc09. She's so Mean",
"Upion Havoc \n 09. She's so Mean")
tracks <- stringr::str_replace(tracks, "07. How Deep Is Your Love -", "07. How Deep Is Your Love - Calvin Harris")
tracks <- stringr::str_replace(tracks, "08 Bumble Bee -", "08 Bumble Bee - Zedd & Botnek")
tracks <- stringr::str_replace(tracks, "Young & Stupid -", "Young & Stupid - Travis Mills feat. T.I.")
tracks <- stringr::str_replace(tracks, "Bpn Jovi", " - Bon Jovi")
tracks <- stringr::str_replace(tracks, "Damn-R", "Damn R")
tracks <- stringr::str_replace(tracks, "Re-Dub", "Re Dub")
tracks <- stringr::str_replace(tracks, "Boom-Lay Boom-Lay Boom", "Boom Lay Boom Lay Boom")
tracks <- stringr::str_replace(tracks, "Hi-Tack", "Hi Tack")
tracks <- stringr::str_replace(tracks, "\\(Calvin Harris Remix\\) Fatboy Slim", "Fatboy Slim")
tracks <- stringr::str_replace(tracks, "B-Tastic", "B Tastic")
tracks <- stringr::str_replace(tracks, "E-Nergy", "E Nergy")
tracks <- stringr::str_replace(tracks, "In the Clear Six60", "In the Clear - Six60")
tracks <- stringr::str_replace(tracks, "Everybody Go! Vice", "Everybody Go! - Vice")
tracks <- stringr::str_replace(tracks, "My Love - feat. T.I. - Justin Timberlake",
"My Love - Justin Timberlake feat. T.I.")
tracks <- stringr::str_replace(tracks, "Original Release \\(PPCA\\)", "")
tracks <- tracks[!stringr::str_detect(tracks, "Get ready for what may be our fiercest release yet")]
After doing this I lied on the floor drenched in sweat / created a tibble.
tracks <- tibble::tibble(track = tracks)
tracks$release <- nrow(tracks):1
Note that the release variable isn’t the actual release number, it’s more a time variable.
At this stage I had one string by release, which I split in one string by track.
tracks$track <- purrr::map(tracks$track, stringr::str_split,
pattern = "\\\n", simplify = FALSE)
tracks$track <- purrr::map(tracks$track, unlist)
tracks <- tidyr::unnest(tracks, track)
The next step was keeping only the 10 first tracks by release, ignoring bonus and alternative tracks listed at the end. It also involved removing useless strings that were not actually songs.
tracks <- dplyr::filter(tracks, track != "")
tracks <- dplyr::filter(tracks, track != " 02. ")
tracks <- dplyr::filter(tracks, track != " 03. ")
tracks <- dplyr::filter(tracks, track != " 04. ")
tracks <- dplyr::filter(tracks, track != " 05. ")
tracks <- dplyr::filter(tracks, track != " 06. ")
tracks <- dplyr::filter(tracks, track != " 07. ")
tracks <- dplyr::filter(tracks, track != " 08. ")
tracks <- dplyr::filter(tracks, track != " 08. ")
tracks <- dplyr::filter(tracks, track != " 09. ")
tracks <- dplyr::filter(tracks, track != " 09. ")
tracks <- dplyr::filter(tracks, track != " 10. ")
tracks <- dplyr::filter(tracks, track != " 10. ")
tracks <- dplyr::filter(tracks, track != " Calvin Harris")
tracks <- dplyr::filter(tracks, track != " Zedd & Botnek")
tracks <- dplyr::filter(tracks, track != " Travis Mills feat. T.I.")
tracks <- dplyr::group_by(tracks, release)
tracks <- dplyr::mutate(tracks, song = 1:n())
tracks <- dplyr::filter(tracks, song <= 10)
tracks <- dplyr::ungroup(tracks)
knitr::kable(tracks[1:10,])
| release | track | song |
|---|---|---|
| 42 | 01. Run Wild - Hardwell feat. Jake Reese | 1 |
| 42 | 02. Go! (Vincent Price Remix) - Wolfpack & Avancada | 2 |
| 42 | 03. Spoken Word - Chase & Status feat. George the Poet | 3 |
| 42 | 04 .LRAD - Knife Party | 4 |
| 42 | 05. Friday - PARRI | 5 |
| 42 | 06. Jungle Youth - Young The Giant | 6 |
| 42 | 07. Ocho Cinco - DJ Snake feat. Yellow Claw | 7 |
| 42 | 08. Feel Your Love - Flux Pavilion & NGHTMRE feat. Jamie Lewis | 8 |
| 42 | 09. Closer - The Chainsmokers feat. Halsey | 9 |
| 42 | 10. Love On The Brain - Rihanna | 10 |
After this I extracted the title and artist of each track. I’m not sure why I needed to change the encoding of the string for that, but before trying this solution I was bothered by there being different sorts of dashes and hyphens.
tracks <- dplyr::mutate(tracks, track = stringr::str_trim(track))
split_title_artist <- function(string, release){
track <- string
Encoding(string) <- "latin1"
# avoid some issues later
string <- stringr::str_replace(string, "â\u0080\u0099", "'")
string <- stringr::str_replace(string, "ï¼\u0088", "(")
string <- stringr::str_replace(string, "¼\u0089", ")")
string <- stringr::str_replace(string, "`", "'")
string <- stringr::str_replace(string, "â\u0080¦", "...")
string <- stringr::str_replace(string, "DéjÃ", "Déjà")
string <- stringr::str_replace(string, "Bbn Jovi", "- Bon Jovi")
string <- stringr::str_replace(string, "Marfia", "Mafia")
string <- stringr::str_replace(string, ":", "")
string <- stringr::str_replace(string, "Diamond Eyes (Boom-Lay Boom-Lay Boom)", "Diamond Eyes (Boom Lay Boom Lay Boom)")
string <- stringr::str_replace(string, "Studio-X", "Studio X")
# hyphens/dashes
string <- stringr::str_replace(string, "â\u0080\u0093", "-")
string <- stringr::str_replace(string, "–", "-")
string <- stringr::str_replace(string, "-", "\u0096")
both <- stringr::str_split(string, pattern = "\u0096",
simplify = TRUE)
tibble::tibble(title = both[1],
artist = both[2],
release = release,
track = track)
}
split_a_release <- function(strings, release){
purrr::map_df(strings, split_title_artist, release)
}
tracks_si <- purrr::map2_df(tracks$track, tracks$release, split_a_release)
tracks <- dplyr::left_join(tracks, tracks_si, by = c("release", "track"))
tracks <- dplyr::mutate(tracks, title = stringr::str_replace(title, "^[0-1]*[0-9]* *\\.*", ""))
When the artist was in fact two artists, I kept only the first one which I assumed to be more informative of the style of the song.
first_artist <- function(artist){
artist <- stringr::str_replace(artist, "\\&.*$", "")
first_artist <- stringr::str_replace(artist, "[fF]eat.*", "")
if(stringr::str_detect(first_artist, "Colourbox")){
first_artist <- "Colourbox"
}
first_artist
}
tracks <- dplyr::mutate(tracks, first_artist = first_artist(tracks$artist))
And I got there:
knitr::kable(tracks[1:10,])
| release | track | song | title | artist | first_artist |
|---|---|---|---|---|---|
| 42 | 01. Run Wild - Hardwell feat. Jake Reese | 1 | Run Wild | Hardwell feat. Jake Reese | Hardwell |
| 42 | 02. Go! (Vincent Price Remix) - Wolfpack & Avancada | 2 | Go! (Vincent Price Remix) | Wolfpack & Avancada | Wolfpack |
| 42 | 03. Spoken Word - Chase & Status feat. George the Poet | 3 | Spoken Word | Chase & Status feat. George the Poet | Chase |
| 42 | 04 .LRAD - Knife Party | 4 | LRAD | Knife Party | Knife Party |
| 42 | 05. Friday - PARRI | 5 | Friday | PARRI | PARRI |
| 42 | 06. Jungle Youth - Young The Giant | 6 | Jungle Youth | Young The Giant | Young The Giant |
| 42 | 07. Ocho Cinco - DJ Snake feat. Yellow Claw | 7 | Ocho Cinco | DJ Snake feat. Yellow Claw | DJ Snake |
| 42 | 08. Feel Your Love - Flux Pavilion & NGHTMRE feat. Jamie Lewis | 8 | Feel Your Love | Flux Pavilion & NGHTMRE feat. Jamie Lewis | Flux Pavilion |
| 42 | 09. Closer - The Chainsmokers feat. Halsey | 9 | Closer | The Chainsmokers feat. Halsey | The Chainsmokers |
| 42 | 10. Love On The Brain - Rihanna | 10 | Love On The Brain | Rihanna | Rihanna |
Track 2: Spotify data downloading
I dreamt of a database giving me the beats per minute, style, etc of each song. I didn’t get any information about the bpm but thanks to the Spotify API and this R package I was able to get information about the artists including their genres and popularity. For songs, the API does not give such information.
Note: the spotifyOAuth part of the following lines demands your first getting an Spotify API app client ID and secret as explained in the README of the package. I saved these as environment variables in my .Renviron.
library("Rspotify")
keys <- spotifyOAuth(app_id = Sys.getenv("SPOTIFY_APPID"),
client_id = Sys.getenv("SPOTIFY_CLIENTID"),
client_secret = Sys.getenv("SPOTIFY_SECRET"))
get_and_wait <- function(artist, keys){
Sys.sleep(1)
info <- searchArtist(artist, token = keys)
if(!is.null(info)){
info <- info[1,]
}
info$first_artist <- artist
info
}
artists_info <- purrr::map_df(unique(tracks$first_artist), get_and_wait, keys)
readr::write_csv(artists_info, path = "data/artists_info.csv")
tracks <- dplyr::left_join(tracks, artists_info, by = "first_artist")
readr::write_csv(tracks, path = "data/tracks.csv")
knitr::kable(artists_info[1:5,])
| display_name | id | popularity | followers | genres | type | first_artist |
|---|---|---|---|---|---|---|
| Hardwell | 6BrvowZBreEkXzJQMpL174 | 78 | 1660846 | big room,deep big room,dutch house,edm,electro house,progressive electro house,progressive house,tropical house | artist | Hardwell |
| Wolfpack | 74ycentHh1YZrW5x4PLnox | 54 | 8554 | crust punk,deep big room,sky room | artist | Wolfpack |
| Chase & Status | 3jNkaOXasoc7RsxdchvEVq | 69 | 300912 | brostep,deep groove house,drum and bass,edm,grime,house,tropical house | artist | Chase |
| Knife Party | 2DuJi13MWHjRHrqRUwk8vH | 64 | 529738 | australian dance,big room,brostep,catstep,complextro,edm,electro house,electronic trap,moombahton,zapstep | artist | Knife Party |
| PARRI$ | 17L4AvcA7zS5xdnLhemEMM | 40 | 7264 | escape room | artist | PARRI |
I got a genres information for 209 out of 313 artists.
Track 3: making sense of the genres of artists
As one sees above, each artist can have several genres and there are a ton of possible genres. When googling a bit about Spotify music genres, I found this gem of a webpage. Impressive! In my case, I wanted to have a few groups of musical genres in order to link them to the track, e.g. is there a musical genre more representative of the biceps track as opposed to other tracks?
I decided to cluster the artists based on the binary variables for each genre. For this I used the klaR::kmodes function because k-modes is a method for clustering based on categorical variables as opposed to k-means for instance. In work that I don’t present here, I played with 1) the number of clusters, looking at the resulting total sum of within-cluster differences and 2) the minimal number of artists that should have a genre for this genre to be included. For instance if a single artist has the style “francoton”, then I don’t want to use it for clustering. In the end, I was quite happy with 6 clusters and keeping only genres that occurred more than 10 times in the data. Doing this there were some artists I couldn’t cluster since they had only been described by very rare genres.
Before clustering I had to transform the data a bit.
artists_info <- readr::read_csv("data/artists_info.csv")
artists_info <- dplyr::filter(artists_info, !is.na(display_name))
artists_info <- dplyr::select(artists_info, - first_artist, - followers)
artists_info <- unique(artists_info)
# most important word?
split_the_genres <- function(genres){
genres <- stringr::str_split(genres, ",")
genres
}
artists_info <- dplyr::filter(artists_info, !is.na(genres))
artists_info <- dplyr::mutate(artists_info, genre = split_the_genres(genres))
artists_info <- tidyr::unnest(artists_info, genre)
artists_info <- dplyr::mutate(artists_info, value = TRUE)
artists_info <- tidyr::spread(unique(artists_info), genre, value, fill = FALSE)
#
# keep only variables with more than 10 occurrence
sum_or_not <- function(x){
if(is.logical(x)){
sum(x) > 10
}else{
TRUE
}
}
variables_info <- dplyr::summarise_all(artists_info, sum_or_not)
artists_info <- artists_info[,as.logical(t(variables_info))]
knitr::kable(artists_info[1:2,])
| display_name | id | popularity | genres | type | alternative metal | big room | brostep | bubblegum dance | dance pop | deep big room | edm | electro house | eurodance | europop | modern rock | neo mellow | nu metal | pop | pop christmas | pop punk | pop rap | pop rock | post-grunge | post-teen pop | progressive electro house | progressive house | r&b | rock | tropical house |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 Doors Down | 2RTUTCvo6onsAnheUk3aL9 | 76 | alternative metal,alternative rock,heavy christmas,nu metal,pop punk,pop rock,post-grunge,rap metal,rock | artist | TRUE | FALSE | FALSE | FALSE | FALSE | FALSE | FALSE | FALSE | FALSE | FALSE | FALSE | FALSE | TRUE | FALSE | FALSE | TRUE | FALSE | TRUE | TRUE | FALSE | FALSE | FALSE | FALSE | TRUE | FALSE |
| 3OH!3 | 0FWzNDaEu9jdgcYTbcOa4F | 68 | dance pop,electropowerpop,modern rock,pop,pop punk,pop rap,post-teen pop | artist | FALSE | FALSE | FALSE | FALSE | TRUE | FALSE | FALSE | FALSE | FALSE | FALSE | TRUE | FALSE | FALSE | TRUE | FALSE | TRUE | TRUE | FALSE | FALSE | TRUE | FALSE | FALSE | FALSE | FALSE | FALSE |
Then the clustering happened.
set.seed(1)
clustering <- klaR::kmodes(artists_info[, 6:ncol(artists_info)], modes = 6)
clustering$size
## cluster
## 1 2 3 4 5 6
## 17 13 22 14 21 84
artists_info$cluster <- clustering$cluster
library("magrittr")
dplyr::filter(artists_info, cluster == 1) %>%
dplyr::select(display_name, genres) %>%
head() %>%
knitr::kable()
| display_name | genres |
|---|---|
| Armin van Buuren | big room,edm,progressive house,progressive trance,trance,tropical house |
| Avicii | big room,dance pop,edm,pop,tropical house |
| Bob Sinclar | disco house,edm,filter house,house,tropical house,vocal house |
| Calvin Harris | edm,electro house,house,pop,progressive house |
| Chase & Status | brostep,deep groove house,drum and bass,edm,grime,house,tropical house |
| David Guetta | dance pop,edm,pop,tropical house |
I then tried to characterize each cluster by its most important genre, well one of them. It’s as arbitrary as the rest of the clustering but I needed to summarize information anyway. I’d be glad to hear about other ideas for categorizing artists!
get_most_important_genre <- function(df){
counts <- as.numeric(t(dplyr::summarize_all(df[, 6:(ncol(df)-1)], sum)))
names(df)[6:(ncol(df)-1)][which(counts == max(counts))][1]
}
styles <- artists_info %>%
split(artists_info$cluster) %>%
purrr::map_chr(get_most_important_genre)
cluster_music <- tibble::tibble(cluster = 1:6,
style = styles)
knitr::kable(cluster_music)
| cluster | style |
|---|---|
| 1 | edm |
| 2 | big room |
| 3 | dance pop |
| 4 | alternative metal |
| 5 | pop |
| 6 | eurodance |
Track 4: Plotting
Once I had my categories for some artists, I was impatient to look at their proportions depending on the muscle group. I first prepared the data in order to have meaningful names for clusters and tracks.
artists_info <- dplyr::select(artists_info, display_name, cluster, id, popularity,
genres)
tracks <- dplyr::left_join(tracks, artists_info,
by = c("display_name", "id", "popularity", "genres"))
library("ggplot2")
theme_set(theme_gray(base_size = 18))
library("viridis")
library("magrittr")
track_muscle <- tibble::tibble(song = 1:10,
muscle = c("warm-up", "squats", "chest",
"back", "triceps", "biceps",
"lunges", "shoulders", "core",
"cool-down"))
tracks <- dplyr::left_join(tracks, track_muscle,
by = "song")
tracks <- dplyr::mutate(tracks,
muscle = forcats::fct_reorder(muscle, song))
tracks <- dplyr::left_join(tracks, cluster_music, by = "cluster")
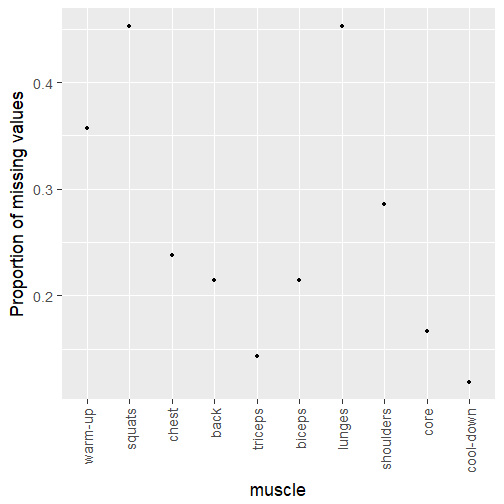
I first made a figure of the number of missing values i.e. missing cluster by muscle group. Sadly some muscle groups seem to have more missing values, hopefully the sample I do have for them is representative. Note that in total I have 42 releases.
tracks %>%
dplyr::group_by(muscle) %>%
dplyr::summarise(prop_na = sum(is.na(cluster))/n()) %>%
ggplot() +
geom_point(aes(muscle, prop_na)) +
ylab("Proportion of missing values")+
theme(axis.text.x = element_text(angle = 90, hjust = 1, vjust = 0.5))
And then I looked at the musical genres by muscle group.
tracks %>%
dplyr::filter(!is.na(cluster)) %>%
ggplot() +
geom_bar(aes(muscle, fill = style),
position = "fill") +
scale_fill_viridis(discrete = TRUE) +
theme(axis.text.x = element_text(angle = 90, hjust = 1, vjust = 0.5))
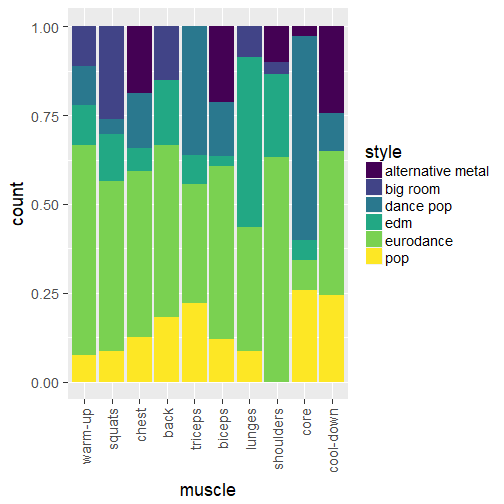
So, is this interesting? I’m not exactly sure, ah! It seems that the shoulders track is associated with less pop or dance than the other tracks, maybe because overhead presses demand more rythm? Cool down does seem more quite with no electronic music (edm and big room) which makes sense. All in all, I was happy to see this plot but would like to have a better categorization of songs and well less missing values. I’m not a good musical analyst yet! Oh and I’d love to get data about beats per minute… Maybe in a next release of this post, by me or one of you dear readers? Oh and if you want music that’s more quiet, check out this post of mine about Radio Swiss Classic program!