One of my more or less guilty pleasures is reading The Guardian blind date each week. I think I started doing this when living in Cambridge, England for five months. I would buy i every weekday and The Guardian week-end every week-end. I wasn’t even dating at the time I discovered The Guardian blind dates but I’ve always liked their format.
I get so much into each date report that seeing both participants say they want to meet again makes me ridiculously happy. I like wondering how matches were made, but today I just want to look into the contents of post-date interviews.
Scraping the data
The first step was scraping the data from The Guardian’s website. Webscraping has gotten quite boring at this point on my blog I guess, but I see no alternative.
Getting links to all articles
The structure of a link to a blind date was quite unpredictable so I scraped all links from the 13 pages like this one.
library("rvest")
library("tidyr")
library("stringr")
library("dplyr")
library("purrr")
get_link <- function(link){
link <- gsub("<a href=.", "", link)
link <- gsub("\".*", "", link)
link
}
get_page_links <- function(page_number){
url <- paste0("https://www.theguardian.com/lifeandstyle/series/blind-date?page=", page_number)
page <- read_html(url)
links <- html_nodes(page, "a")
text <- html_text(links)
links <- links[which(stringr::str_detect(text, "Blind date"))]
links <- purrr::map_chr(links, get_link)
links <- unique(links)
return(links)
}
all_links <- purrr::map(1:13, get_page_links)
all_links <- unlist(all_links)
head(all_links)
## [1] "https://www.theguardian.com/lifeandstyle/2017/apr/01/blind-date-id-planned-my-escape-dan-jack"
## [2] "https://www.theguardian.com/lifeandstyle/2017/mar/25/blind-date-bex-fashion-pr-meets-henry-civil-servant"
## [3] "https://www.theguardian.com/lifeandstyle/2017/mar/18/blind-date-i-mistook-a-waiter-for-my-date"
## [4] "https://www.theguardian.com/lifeandstyle/2017/mar/11/blind-date-we-talked-about-having-children"
## [5] "https://www.theguardian.com/lifeandstyle/2017/mar/04/blind-date-damola-karen"
## [6] "https://www.theguardian.com/lifeandstyle/2017/feb/25/blind-date-david-mary"
Doing this I found 434 links. How exciting!
Extract content from each article
Then for each article I tried to extract answers to 8 questions. I’ve seen at least one example with not exactly these questions which was a shock although the question “Would you follow them on social media?” is great.
I first wrote down all the classical questions.
questions <- tibble::tibble(number = 1:8,
question = c("First impressions",
"What did you talk about\\?",
"Any awkward moments\\?",
"Good table manners\\?",
"Best thing about",
"Did you go on somewhere\\?",
"Marks out of 10\\?",
"Would you meet again\\?"))
Then I defined the function for getting answers to one question, taking into account the fact that this question was maybe not asked. The function is used in a function for scraping pages.
for_one_question <- function(question, content, link){
answer <- content[which(stringr::str_detect(content, question))]
answer <- str_replace(answer, ".*<br\\/>", "")
answer <- str_replace(answer, question, "")
answer <- str_replace(answer, "<\\/p>", "")
answer <- str_replace(answer, question, "")
answer <- str_replace(answer, "<p><strong>", "")
answer <- str_replace(answer, "<\\/strong>", "")
answer <- trimws(answer)
if(length(answer) > 0){
data.frame(question = rep(question, 2),
answer = answer, which = 1:2,
link = rep(link, 2))
}else{
NULL
}
}
scrape_page <- function(link){
print(link)
content <- read_html(link)%>%
html_nodes("p") %>%
as.character()
answers <- map(questions$question, for_one_question,
content = content,
link = link)
answers <- suppressWarnings(bind_rows(answers))
}
And at last I could scrape all the data, that I gitignored for not making public something I’m not sure I can.
results <- map(all_links, scrape_page) %>% bind_rows()
readr::write_csv(results, path = "data/2017-03-07-blinddates_allanswers.csv")
| question | answer | which | link |
|---|---|---|---|
| First impressions | Cool, comfortable, cultured. | 1 | https://www.theguardian.com/lifeandstyle/2017/mar/04/blind-date-damola-karen |
| First impressions | He was very warm, friendly and dynamic. | 2 | https://www.theguardian.com/lifeandstyle/2017/mar/04/blind-date-damola-karen |
| What did you talk about? | Our families, travelling, religion, how much we both like Jamiroquai, and what it would be like living on Mars. Or a desert island. Or a desert island on Mars. Who would win: giant spider v giant octopus? The usual. | 1 | https://www.theguardian.com/lifeandstyle/2017/mar/04/blind-date-damola-karen |
| What did you talk about? | Life’s zigzags, comedy, Mars. | 2 | https://www.theguardian.com/lifeandstyle/2017/mar/04/blind-date-damola-karen |
| Any awkward moments? | When the manager raced out of the restaurant as we were saying goodbye. We thought he was going to slap us with a crazy bill. He was just coming to say goodbye. | 1 | https://www.theguardian.com/lifeandstyle/2017/mar/04/blind-date-damola-karen |
| Any awkward moments? | We were seated at different tables at the beginning. | 2 | https://www.theguardian.com/lifeandstyle/2017/mar/04/blind-date-damola-karen |
For a Guardian blind date fan like myself, getting all this data was really cool.
Analysing blind dates
This is a quite wrong section title since I won’t do any fancy analysis. I want to look at only part of the classical questions.
So what did they talk about?
For knowing what people talked about in all these dates, I’ll look for the most common words. Note that I’m not looking at the consistency between date participants answers (in theory you should have talked about the same things as the other person on your date, but human memory isn’t perfect), and I’ll use all answers together. I remove stopwords and words related to html formatting or links in the answers.
library("tidytext")
library("rcorpora")
what <- filter(results, question == "What did you talk about\\?")
stopwords <- corpora("words/stopwords/en")$stopWords
what_words <- what %>%
unnest_tokens(word, answer) %>%
count(word, sort = TRUE) %>%
filter(!word %in% stopwords) %>%
filter(!word %in% c("href", "http",
"strong", "link",
"https", "title",
"data", "body",
"class", "underline"))
knitr::kable(head(what_words, n = 10))
| word | n |
|---|---|
| work | 98 |
| music | 90 |
| food | 88 |
| travel | 85 |
| london | 84 |
| meet | 82 |
| family | 74 |
| jobs | 66 |
| friends | 55 |
| travelling | 50 |
Remember we’re looking at 434 blind dates and in particular 828 answers. So these unsurprising common themes are not that common, but then people might have used synonyms.
What grade did they give each other?
I agree that giving a grade out of 10 to your date can be a bit cruel, especially when this grade will be published in a famous newspaper, but then people get free food and often a nice evening and know about it so I guess it’s ok? In any case, I decided to extract the grades they gave each other. For this I had to use regular expressions because some people don’t only give a number, they explain their choice.
I keep only dates with two answers to the question, and for each answer I want to have only one possible grade and it has to be between 0 and 10.
grades <- filter(results, question == "Marks out of 10\\?")
grades <- mutate(grades, answer = str_replace(answer, "\\/10", ""))
grades <- mutate(grades, answer = str_replace(answer, "out of 10", ""))
get_grade <- function(df){
grade <- as.numeric(unlist(str_match_all(df$answer, "[:digit:][\\.]?[:digit:]?")))
grade <- grade[!is.na(grade)]
grade <- grade[grade <= 10]
if(length(grade) != 1){
999
}else{
grade
}
}
grades <- by_row(grades, get_grade,
.to = "grade", .collate = "cols")
grades <- filter(grades, grade != 999)
grades <- group_by(grades, link)
grades <- filter(grades, n() == 2)
grades <- ungroup(grades)
select(grades, answer, grade) %>% head() %>% knitr::kable()
| answer | grade |
|---|---|
| 8. | 8 |
| 7. | 7 |
| A strong 7 for a great evening of conversation and laughs. | 7 |
| 8. | 8 |
| 7. | 7 |
| 10. | 10 |
Now I can see which grades were given and most importantly how different both grades are.
I have 522 grades which means grades for 261 dates out of 434 dates which is a bit disappointing but hopefully still a representative sample. Also I’m not sure the problem is my code, sometimes people just don’t want to give a grade so they give several or write some sort of explanation with words.
library("ggplot2")
library("hrbrthemes")
ggplot(grades) +
geom_histogram(aes(grade)) +
theme_ipsum_rc() +
labs(title="Grades given by Guardian blind dates participants",
subtitle="See how I use Bob Rudis' nice theme",
caption="Thank God for webscraping and regex")
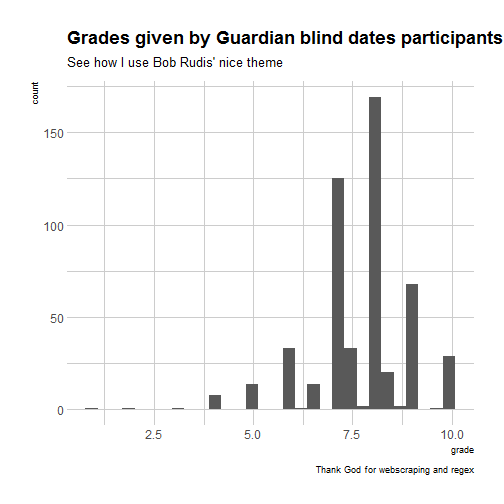
Ok now we all want to know what date was catastrophic enough for someone to get a small grade.
filter(grades, grade == min(grade)) %>% .$link
## [1] "https://www.theguardian.com/lifeandstyle/2012/jun/29/blind-date"
So now please all stop being sad, the actual answer was “Would it be cheeky to say the same as her and add 1?”! Which shows the limits of my code and how nice people seem to be to each other in this small sample (although maybe they’re just nice because they want the other one to be nice as well)? And to answer the participant’s question, I’d say it’s not cheeky but not analysis-friendly.
Now, did people give each other close grades?
grades <- group_by(grades, link)
grades <- summarize(grades, diff = abs(grade[1] - grade[2]))
ggplot(grades) +
geom_histogram(aes(diff)) +
theme_ipsum_rc()+
labs(title="Difference between grades")
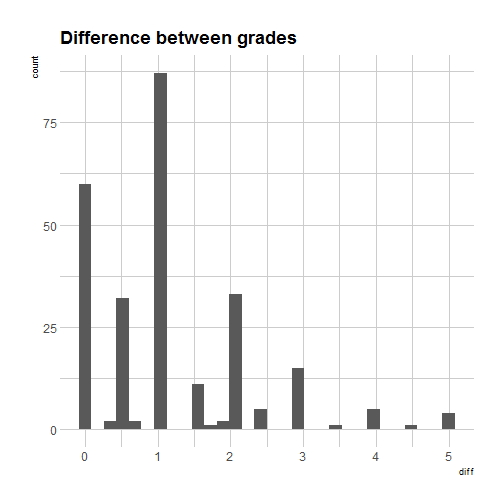
To me it seems grades are pretty close, but more than an agreement it might indicate most people choose some sort of common grade no matter the date because they’re not keen on giving grades?
Did they want to meet again?
For finding out whether people would like to meet again, I decided to use sentiment analysis because I had no other better idea and I think it makes this post quite well-rounded with term frequency, number extraction and sentiment analysis. So please give me a good grade!
I used code from one tidytext vignette.
meet <- filter(results, question == "Would you meet again\\?")
bing <- get_sentiments("bing")
meetsentiment <- meet %>%
mutate(savedanswer = answer) %>%
unnest_tokens(word, answer)%>%
inner_join(bing) %>%
count(link, which, savedanswer, sentiment) %>%
spread(sentiment, n, fill = 0) %>%
mutate(sentiment = positive - negative) %>%
filter(!is.na(sentiment))
So how often did one of them want to meet the other again?
ggplot(meetsentiment) +
geom_bar(aes(sentiment)) +
theme_ipsum_rc()
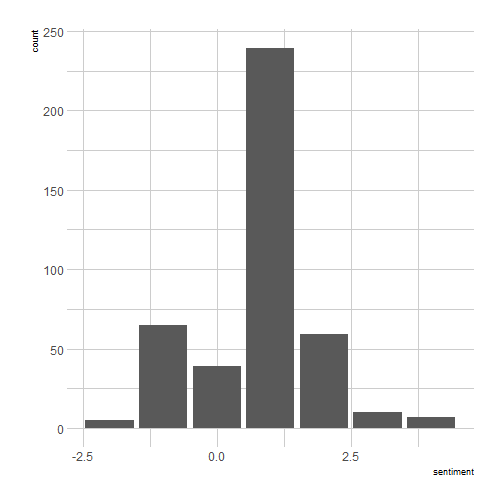
To get an idea of how good my sentiment analysis is working – probably not well, let’s look at the extremes.
filter(meetsentiment, sentiment <0) %>%
head() %>% knitr::kable()
| link | which | savedanswer | negative | positive | sentiment |
|---|---|---|---|---|---|
| https://www.theguardian.com/lifeandstyle/2009/apr/11/blind-date-cash-coryton | 2 | I don’t think we’ll arrange anything, but Brighton is a small place and we’d stop to chat if we bumped into each other. | 1 | 0 | -1 |
| https://www.theguardian.com/lifeandstyle/2009/aug/01/blind-date | 2 | I’m sure we will – it would be a shame not to. | 1 | 0 | -1 |
| https://www.theguardian.com/lifeandstyle/2009/feb/28/blind-date-relationships | 1 | We swapped numbers, but I don’t think there will be any romance, sadly. | 1 | 0 | -1 |
| https://www.theguardian.com/lifeandstyle/2009/feb/28/blind-date-relationships | 2 | She didn’t seem that interested, so I doubt it. | 1 | 0 | -1 |
| https://www.theguardian.com/lifeandstyle/2009/may/02/ian-winterton-jane-thomas | 1 | I would but she lives in the Wirral, so it’s unlikely to happen that often. | 1 | 0 | -1 |
| https://www.theguardian.com/lifeandstyle/2009/oct/24/blind-date | 2 | We did the number swap thing, so it would be a shame not to. | 1 | 0 | -1 |
So actually it’s not too bad on this small subset although “a shame not to” shouldn’t be sorted in this category.
filter(meetsentiment, sentiment >3) %>%
head() %>% knitr::kable()
| link | which | savedanswer | negative | positive | sentiment |
|---|---|---|---|---|---|
| https://www.theguardian.com/lifeandstyle/2010/aug/07/blind-date | 1 | It was fun and Ali was very nice, but could I ever love a woman who doesn’t like Morrissey? That was a deal breaker, I’m afraid. | 1 | 5 | 4 |
| https://www.theguardian.com/lifeandstyle/2010/aug/14/blind-date | 1 | Only as friends. I wasn’t physically attracted to Matt, but found him to be a warm, charming and very nice bloke. | 0 | 4 | 4 |
| https://www.theguardian.com/lifeandstyle/2010/aug/21/blind-date | 2 | I enjoyed the night and thought we got on really well, but I’m not sure if we’ll arrange to meet up again. We’re both going to the same music festival in September, so it would be great to run into her and catch up then. | 0 | 4 | 4 |
| https://www.theguardian.com/lifeandstyle/2010/dec/11/blind-date | 1 | Definitely for drinks as friends. We’ve already said we’ll meet up soon – Mal has promised to show me how to dance properly to jungle music, although I may be better than him as it stands. | 0 | 4 | 4 |
| https://www.theguardian.com/lifeandstyle/2010/nov/06/blind-date | 2 | No – we had very little in common. But it’s a mark of what good company she is that I still managed to have a lovely evening! | 0 | 4 | 4 |
| https://www.theguardian.com/lifeandstyle/2010/oct/30/blind-date | 2 | She’s great fun, so it’d be good to see her again sometime. | 0 | 4 | 4 |
Mmmh so here it works much less well. I should maybe weight by length of the sentence because apparently “just as friends” sometimes needs many compliments to make it less hurtful. But then given the efforts I invested in automatically sorting the answers (close to zero), I can’t complain and will leave this as is.
Last words
I could have done more with this dataset! Ideas I have include also extracting age and profession of the participants, and find which industries are the most represented/compatible using my R monkeylearn package as I did in my #first7jobs analysis. I have also noticed the address of the restaurant where people had dinner is written at the end of each post, which makes me want to geocode them all with opencage. But what would motivate me even more would be to use Scott Chamberlain’s charlatan package to create false names and jobs of dates, and then rcorpora to generate their false interviews. If I did that I could read one “Guardian” blind date per day instead of one per week!
To end on a more serious note, Guardian journalists report on other important stuff such as politics and the environment, so if you can please consider becoming a Guardian Supporter. My husband and I did and we’re quite happy we did!