These last days a trending Twitter hashtag was “#actuallivingscientist”, whose origin can be find in this convo and whose original goal was to allow scientists to present themselves to everyone, a sort of #scicomm action. A great initiative, because we need science and we need everyone to know how it’s done, by actual human beings.
I didn’t tweet with the hashtag, but I consider myself a scientist with more or less experience in different fields – and my last post was about the scientist I married. In my timeline thanks to Auriel Fournier there were many tweets of ecologists studying animals. I’d like to say cute animals but some were carcasses… But still, it made me want to quantify which animals were the most present in the tweets. Any bet?
Getting tweets
I got tweets thanks to Mike Kearney’s rtweet package. I’ve done something similar in the past for #firstsevenjobs tweets.
library("rtweet")
library("dplyr")
actual <- search_tweets(q = "#actuallivingscientist",
include_rts = FALSE,
n = 18000, type = "recent")
# no need for coordinates which are often missing
actual <- select(actual, - coordinates)
# only English
actual <- filter(actual, lang == "en")
# no answers
actual <- filter(actual, is.na(in_reply_to_user_id))
# save
save(actual, file = "data/2017-02-05-actuallivingscientists.RData")
actual
## # A tibble: 6 × 22
## created_at status_id
## <dttm> <chr>
## 1 2017-02-05 08:14:53 828154916959088640
## 2 2017-02-05 08:11:17 828154013656952832
## 3 2017-02-05 08:11:04 828153957797261312
## 4 2017-02-05 08:06:18 828152756112351233
## 5 2017-02-05 08:04:27 828152292532695040
## 6 2017-02-05 08:02:55 828151908531568640
## # ... with 20 more variables: text <chr>, source <chr>,
## # in_reply_to_status_id <chr>, in_reply_to_user_id <chr>,
## # in_reply_to_screen_name <chr>, is_quote_status <lgl>,
## # retweet_count <int>, favorite_count <int>, lang <chr>,
## # quoted_status_id <chr>, user_id <chr>, screen_name <chr>,
## # mentions_user_id <chr>, mentions_screen_name <chr>, hashtags <chr>,
## # urls <chr>, is_retweet <lgl>, retweet_status_id <lgl>,
## # place_name <chr>, country <chr>
Doing this I obtained 9611 tweets. Now let’s look for animals in them!
Looking for animals
Note: if Monkeylearn had an “animal extractor” module, I’d have tested a different approach with my own package but it would have been really close to my #firstsevenjobs post a.k.a. as boring for you!
I have to confess I had never used Julia Silge’s and David Robinson’s tidytext package before. I read Julia blog (you should do that too!) though so I knew about the post where she looked for the names of states in songs using tidytext, in particular a function calling Lincoln Mullen’s tokenizers package to split each song into words and bigrams (combinations of two words). I wanted to reproduce the approach, for this I only needed a list of animals and remembered Gabor Csardi’s rcorpora package, which contains all datasets from these corpora. Including a list of animals, y’all!
library("rcorpora")
head(corpora("animals/common")$animals)
## [1] "aardvark" "alligator" "alpaca" "antelope" "ape" "armadillo"
A few animals are bigrams, for instance “grizzly bear” so I’ll really use the exact same approach and code as Julia in her songs post. In case you think I often end up copy-pasting R code from other people in my blog posts, please know that I often end up copy-pasting R code from other people in general when I do something for the first time.
library("tidytext")
actual <- tibble::as_tibble(actual)
tidy_tweets <- bind_rows(actual %>%
unnest_tokens(animal_for_detect, text),
actual %>%
unnest_tokens(animal_for_detect, text,
token = "ngrams", n = 2))
tidy_tweets <- select(tidy_tweets, animal_for_detect, everything())
head(tidy_tweets)
## # A tibble: 6 × 22
## animal_for_detect created_at status_id
## <chr> <dttm> <chr>
## 1 hi 2017-02-05 08:14:53 828154916959088640
## 2 i'm 2017-02-05 08:14:53 828154916959088640
## 3 masha 2017-02-05 08:14:53 828154916959088640
## 4 i'm 2017-02-05 08:14:53 828154916959088640
## 5 actuallivingscientist 2017-02-05 08:14:53 828154916959088640
## 6 studying 2017-02-05 08:14:53 828154916959088640
## # ... with 19 more variables: source <chr>, in_reply_to_status_id <chr>,
## # in_reply_to_user_id <chr>, in_reply_to_screen_name <chr>,
## # is_quote_status <lgl>, retweet_count <int>, favorite_count <int>,
## # lang <chr>, quoted_status_id <chr>, user_id <chr>, screen_name <chr>,
## # mentions_user_id <chr>, mentions_screen_name <chr>, hashtags <chr>,
## # urls <chr>, is_retweet <lgl>, retweet_status_id <lgl>,
## # place_name <chr>, country <chr>
Now for the animals data.frame I need names of animals in singular and plural form because tweets might contain animals in both forms. I first decided to just paste an “s” to the names since it’d work most of the time but then I realized Bob Rudis has a package for pluralizing and singularizing any English word, pluralizer.
library("pluralize")
animals <- tibble::tibble(animal_for_detect = corpora("animals/common")$animals)
animals <- mutate(animals, animal = animal_for_detect)
animals <- mutate(animals, animal_for_detect = pluralize(animal_for_detect)) %>%
bind_rows(animals)
animals
## # A tibble: 268 × 2
## animal_for_detect animal
## <chr> <chr>
## 1 aardvarks aardvark
## 2 alligators alligator
## 3 alpacas alpaca
## 4 antelopes antelope
## 5 apes ape
## 6 armadillos armadillo
## 7 baboons baboon
## 8 badgers badger
## 9 bats bat
## 10 bears bear
## # ... with 258 more rows
Much more elegant than my “let’s paste s” approach and I learnt that the plural of buffalo is buffalo! Also “mouses” wouldn’t be as useful as “mice”.
Now I can join the two tables and like Julia in her post I’ll only keep one occurence of an animal per tweet.
tidy_tweets <- inner_join(tidy_tweets, animals,
by = "animal_for_detect") %>%
distinct(status_id, animal, .keep_all = TRUE)
tidy_tweets <- select(tidy_tweets, animal_for_detect, animal, everything())
tidy_tweets
## # A tibble: 560 × 23
## animal_for_detect animal created_at status_id
## <chr> <chr> <dttm> <chr>
## 1 rats rat 2017-02-05 07:53:28 828149527987171328
## 2 leopard leopard 2017-02-05 07:52:33 828149297208233985
## 3 cat cat 2017-02-05 06:57:34 828135460237094919
## 4 fish fish 2017-02-05 06:26:14 828127576996487168
## 5 turtles turtle 2017-02-05 06:22:58 828126753805783044
## 6 squirrel squirrel 2017-02-05 06:12:04 828124011431342080
## 7 snake snake 2017-02-05 06:07:47 828122933390225409
## 8 gorillas gorilla 2017-02-05 05:49:30 828118330473140224
## 9 sheep sheep 2017-02-05 05:39:01 828115691572125696
## 10 parrots parrot 2017-02-05 05:34:55 828114661027504129
## # ... with 550 more rows, and 19 more variables: source <chr>,
## # in_reply_to_status_id <chr>, in_reply_to_user_id <chr>,
## # in_reply_to_screen_name <chr>, is_quote_status <lgl>,
## # retweet_count <int>, favorite_count <int>, lang <chr>,
## # quoted_status_id <chr>, user_id <chr>, screen_name <chr>,
## # mentions_user_id <chr>, mentions_screen_name <chr>, hashtags <chr>,
## # urls <chr>, is_retweet <lgl>, retweet_status_id <lgl>,
## # place_name <chr>, country <chr>
So, what are the animals of actual living scientists?
After doing this, I can at last have a look the frequency of animals in the tweets!
animal_counts <- tidy_tweets %>%
group_by(animal) %>%
summarise(n = n()) %>%
arrange(desc(n))
animal_counts
## # A tibble: 75 × 2
## animal n
## <chr> <int>
## 1 fish 77
## 2 bat 42
## 3 dog 35
## 4 reptile 33
## 5 cat 28
## 6 frog 27
## 7 turtle 23
## 8 snake 22
## 9 parrot 21
## 10 lizard 17
## # ... with 65 more rows
“cat” and “dog” get good rankings but they also are pets and I’ve even seen a tweet saying “I’m not an #actuallivingscientist but I have cute cats”. This is still relevant for the hashtag because on the internet cats are always relevant, but it means we should be careful when interpreting these rankings. Also note that Cat can be someone’s first name (like Salmon can be someone’s last name). In honour of the cover of the tidytext book, let’s look at rabbit tweets.
rabbit_tweets <- filter(tidy_tweets, animal == "rabbit")$status_id
filter(actual, status_id %in% rabbit_tweets)$text
## [1] "This #actuallivingscientist hashtag is pretty great. Excuse me while I fall down the rabbit hole... https://t.co/hZFWOTLDlR"
## [2] "Hi! I'm an #actuallivingscientist studying the smallest rabbit that only occurs in the sagebrush-steppe of the west
https://t.co/9vzi8bOeQF"
## [3] "#DressLikeAWoman #actuallivingscientist are the rabbit hole you need today. https://t.co/fR0ai0kSvn"
Mmmh so only one real occurence of a rabbit studying person in the tweets I collected. What about turtles?
turtle_tweets <- filter(tidy_tweets, animal == "turtle")$status_id
filter(actual, status_id %in% turtle_tweets)$text %>% head()
## [1] "Hi, I'm Katie and I'm an #ActualLivingScientist. I study sea turtles and conservation in Brazil! <f0><U+009F><U+0098><U+008A><f0><U+009F><U+0090><U+00A2> #DressLikeAWoman https://t.co/nTn5v5sctx"
## [2] "#actuallivingscientist #DressLikeAWoman getting our community group to sea turtle conservation meeting in Sinaloa M
https://t.co/IAEMB6X10f"
## [3] "https://t.co/pM09T2lB9Y\nHelping to save Australia's turtles #actuallivingscientist"
## [4] "I'm an evolutionary biologist who likes turtles (and ants). #DressLikeAWoman #actuallivingscientist https://t.co/x3tE3Drv7v"
## [5] "My name is J. I'm an #actuallivingscientist studying oceans, migration, conservation & human emotion. I like turtle
https://t.co/WBMyoAplki"
## [6] "I'm Sara. I'm an #ActualLivingScientist studying sea turtles in Georgia, USA! @sweaverflies: snap/insta, during sum
https://t.co/rY5DIj8j77"
Although I recognize the limitations of my approach, I’ll now make a bar plot of the frequencies of the animals for animals with more than 5 occurences.
library("ggplot2")
library("viridis")
animal_counts <- animal_counts %>%
mutate(animal = ifelse(n < 5, "others", animal)) %>%
group_by(animal) %>%
summarize(n = sum(n)) %>%
arrange(desc(n))
animal_counts <- mutate(animal_counts,
animal = factor(animal,
ordered = TRUE,
levels = unique(animal)))
ggplot(animal_counts) +
geom_bar(aes(animal, n, fill = animal), stat = "identity")+
scale_fill_viridis(discrete = TRUE, option = "plasma")+
theme(axis.text.x = element_text(angle = 45,
hjust = 1,
vjust = 1),
text = element_text(size=15),
legend.position = "none")
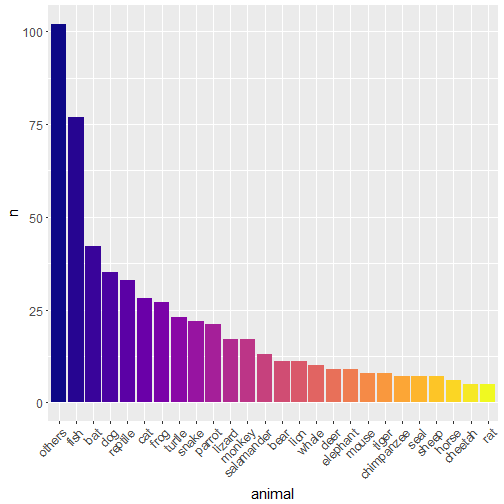
I was amazed at the diversity of animals of the tweets, many of them being research subjects. I like my current research field a lot, but how cool is ecology or biology of animals? Keep up the good work folks!